本教程所有源码下载链接:https://share.weiyun.com/5xmFeUO 密码:fzwh6g
Selenium WebDriver的用法 简介与安装 Selenium WebDriver的简介与安装 Selenium 是一个自动化测试工具,WebDriver是它提供的一套操作浏览器的API,由于WebDriver针对多种编程语言都实现了这些API,因此它可以支持多种编程语言。
从Python语言角度来讲,WebDriver是Python的一个用于实现自动化操作的第三方库。
安装方法:
PhantomJS简介与安装 原文简介:
PhantomJS is a headless web browser scriptable with JavaScript. It runs on Windows, macOS, Linux, and FreeBSD.
白话文简介:
PhantomJS是一个无头的web浏览器,可以用JavaScript编写脚本。它运行在Windows、macOS、Linux和FreeBSD上。
Windows系统安装方法:
1 2 1. 下载 https://bitbucket.org/ariya/phantomjs/downloads/phantomjs-2.1.1-windows.zip 2. 将`phantomjs.exe`所在目录增加到环境变量中
Mac OS X系统安装方法:
建议使用HomeBrew工具进行安装:
Selenium用法 体验入门 首先,我们在ipython中,测试一下Selenium调用WebDriver的API,驱动Chrome浏览器打开我的博客首页的用法:
1 2 3 4 5 6 7 In [2 ]: from selenium import webdriver In [3 ]: browser = webdriver.Chrome() In [4 ]: browser.get('https://sunjiajia.com' )
是不是很简单?
安装geckodriver和chromedriver 注意:
如果在运行browser = webdriver.Firefox()或者browser = webdriver.Chrome()的时候,出现如下错误:
1 WebDriverException: Message: 'geckodriver' executable needs to be in PATH.
或者
1 WebDriverException: Message: 'chromedriver' executable needs to be in PATH. Please see https://sites.google.com/a/chromium.org/chromedriver/home
那么需要配置geckodriver和chromedriver。具体配置方法如下:
Windows配置geckodriver:
1 2 3 4 5 1. 如果Firefox是32位的,请下载 https://github.com/mozilla/geckodriver/releases/download/v0.21.0/geckodriver-v0.21.0-win32.zip 2. 如果firefox是64位的,请下载 https://github.com/mozilla/geckodriver/releases/download/v0.21.0/geckodriver-v0.21.0-win64.zip 3. 将解压后的geckodriver.exe配置到环境变量中
Windows配置chromedriver:
1 2 3 1. 访问http://chromedriver.chromium.org/downloads,查看与自己Chrome版本对应的chromedriver 2. 下载https://chromedriver.storage.googleapis.com/2.40/chromedriver_win32.zip 3. 将解压后的chromedriver.exe配置到环境变量中
Mac OS X配置两种驱动的方法:
1 2 brew install geckodriver brew cask install chromedriver
Linux配置两种驱动的方法:
1 2 3 下载linux队形的driver,将其放入/usr/bin目录下就可以了。如果没有执行权限,加上执行权限。 sudo chmod +x /usr/bin geckodriver sudo chmod +x /usr/bin chromedriver
Selenium WebDriver的基本用法 页面搜索框提交数据 用这样一个案例,来体验获取网页源码和元素的流程:
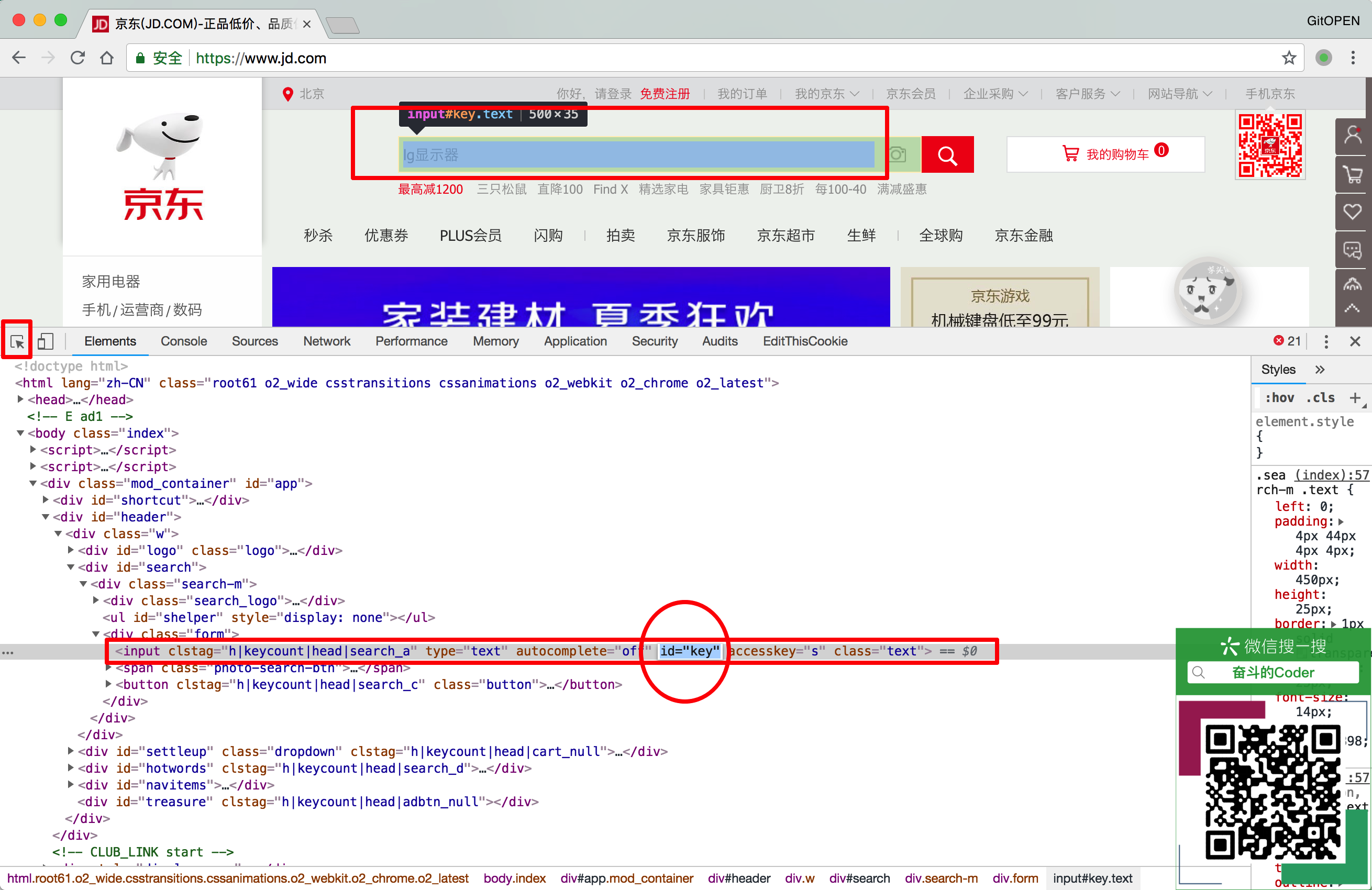
在浏览器中浏览https://www.jd.com,并打开开发者工具,确定页面搜索框的id为id='key',如图所示:
在ipython中编写代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 In [7 ]: from selenium import webdriver In [8 ]: from selenium.webdriver.common.keys import Keys In [9 ]: browser = webdriver.Chrome() In [10 ]: browser.get('https://www.jd.com' ) In [11 ]: ele_search = browser.find_element_by_id('key' ) In [12 ]: ele_search.send_keys('书包' ) In [13 ]: ele_search.send_keys(Keys.ENTER) In [16 ]: from bs4 import BeautifulSoup In [17 ]: soup = BeautifulSoup(browser.page_source,'lxml' ) In [18 ]: tag_title = soup.find('title' ) In [19 ]: tag_title Out[19]: <title>书包 - 商品搜索 - 京东</title>
获取页面元素的方法 假如我们有这样一个标签:
1 <input name ='username' type ='text' id ='user' />
那么获取这个元素的方法可以用:
1 2 3 4 element = driver.find_element_by_id("user" ) element = driver.find_element_by_name("username" ) element = driver.find_elements_by_tag_name("input" ) element = driver.find_element_by_xpath("//input[@id='user']" )
我们在ipython中测试一下这些用法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 In [3 ]: browser=webdriver.Chrome() In [4 ]: browser.get('http://localhost:63342/codes/lesson05/selenium_demo01.html?_ijt=ai9c4f63mslt0q8a4vb93t7c9l' ) In [5 ]: browser.find_element_by_id('user' ) Out[5 ]: <selenium.webdriver.remote.webelement.WebElement (session="bb336a8045d9536ef7b79e16d5a78637" , element="0.6577164491799441-1" )> In [6 ]: browser.find_element_by_name('username' ) Out[6 ]: <selenium.webdriver.remote.webelement.WebElement (session="bb336a8045d9536ef7b79e16d5a78637" , element="0.6577164491799441-1" )> In [7 ]: browser.find_element_by_tag_name('input' ) Out[7 ]: <selenium.webdriver.remote.webelement.WebElement (session="bb336a8045d9536ef7b79e16d5a78637" , element="0.6577164491799441-1" )> In [8 ]: browser.find_element_by_xpath('//input[@id="user"]' ) Out[8 ]: <selenium.webdriver.remote.webelement.WebElement (session="bb336a8045d9536ef7b79e16d5a78637" , element="0.6577164491799441-1" )>
注意: 使用xpath来进行寻找页面元素,如果页面上有多个元素和xpath匹配,那么只会返回第一个匹配的元素。如果没有找到,则会出现NoSuchElementException的异常。
向页面发送数据并操作 当获取到了元素以后,就可以向input框输入内容了,并且使用Keys这个类模拟点击某个按键。
在ipython中测试一下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 In [23 ]: browser = webdriver.Chrome() In [24 ]: browser.get('http://localhost:63342/codes/lesson05/selenium_demo01.html?_ijt=mdvqb7hj3nub56tb9mqm4suktr' ) In [25 ]: ele_input = browser.find_element_by_xpath('//input[@id="user"]' ) In [26 ]: ele_submit = browser.find_element_by_xpath('//input[@type="submit"]' ) In [27 ]: ele_input.send_keys("书包" ) In [28 ]: ele_input.send_keys("鼠标" ) In [29 ]: ele_input.clear() In [30 ]: ele_input.send_keys("鼠标" ) In [31 ]: ele_submit.click() In [32 ]: browser.back()
向下拉框输入数据 我们在ipython中进行测试和学习:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 In [1 ]: from selenium import webdriver In [2 ]: from selenium.webdriver.common.keys import Keys In [3 ]: from bs4 import BeautifulSoup In [4 ]: browser = webdriver.Chrome() In [6 ]: browser.get("http://localhost:63342/codes/lesson05/selenium_demo01.html?_ijt=7c1snu6luuco68a1hc3p3aki85" ) In [7 ]: ele_select = browser.find_element_by_id('province' ) In [9 ]: eles_option = browser.find_elements_by_tag_name('option' ) In [10 ]: for option in eles_option: ...: print(option.get_attribute('value' )) ...: option.click() ...: bj sh gz zz
其实,Selenium WebDriver提供了一个Select方法,可以方便的对下拉框进行操作,回到ipython环境下:
1 2 3 4 5 6 7 8 9 10 11 In [11 ]: from selenium.webdriver.support.ui import Select In [12 ]: ele_select = Select(browser.find_element_by_name('province' )) In [13 ]: ele_select.select_by_index(0 ) In [17 ]: ele_select.select_by_index(1 ) In [18 ]: ele_select.select_by_value('zz' ) In [19 ]: ele_select.select_by_visible_text('北京' )
多选框输入数据 熟悉了单选框的操作,下面来看一下多选框的输入数据,回到ipython环境中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 In [45 ]: browser = webdriver.Chrome() In [46 ]: browser.get('http://localhost:63342/codes/lesson05/selenium_demo01.html?_ijt=8838lsi704td3g3va8uoqc6bhb' ) In [47 ]: ele_select = Select(browser.find_element_by_id('fruits' )) In [48 ]: ele_select.is_multiple Out[48 ]: True In [49 ]: ele_select.select_by_index(0 ) In [50 ]: ele_select.select_by_index(1 ) In [51 ]: ele_select.select_by_index(2 ) In [53 ]: ele_select.select_by_value('pg' ) In [55 ]: ele_select.all_selected_options Out[55 ]: [<selenium.webdriver.remote.webelement.WebElement (session="8b62401cbaeed777430915d8d2b4d834" , element="0.9216159265436044-2" )>, <selenium.webdriver.remote.webelement.WebElement (session="8b62401cbaeed777430915d8d2b4d834" , element="0.9216159265436044-3" )>, <selenium.webdriver.remote.webelement.WebElement (session="8b62401cbaeed777430915d8d2b4d834" , element="0.9216159265436044-4" )>, <selenium.webdriver.remote.webelement.WebElement (session="8b62401cbaeed777430915d8d2b4d834" , element="0.9216159265436044-5" )>] In [56 ]: for option in ele_select.all_selected_options: ...: print(option.get_attribute('value' )) ...: xj xg xhs pg In [57 ]: ele_select.deselect_by_index(0 ) In [58 ]: ele_select.deselect_all()
浏览器的前进后退功能 使用Selenium WebDriver的API控制浏览器的前进后退功能,回到ipython环境中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 In [60 ]: browser = webdriver.Chrome() In [62 ]: browser.get('https://www.baidu.com' ) In [63 ]: ele_input = browser.find_element_by_name('wd' ) In [64 ]: ele_input.send_keys('sunjiajia.com' ) In [65 ]: ele_submit = browser.find_element_by_id('su' ) In [66 ]: ele_submit.click() In [67 ]: ele_next = browser.find_element_by_class_name('n' ) In [68 ]: ele_next.click() In [69 ]: ele_next.click() In [70 ]: ele_next = browser.find_element_by_class_name('n' ) In [71 ]: ele_next.click() In [74 ]: ele_next = browser.find_elements_by_class_name('n' )[-1 ] In [75 ]: ele_next.click() In [77 ]: ele_next = browser.find_elements_by_class_name('n' )[-1 ] In [78 ]: ele_next.click() In [79 ]: browser.back() In [80 ]: browser.forward()
Cookies操作 我们在爬虫的过程中,不可避免的就是遇到登录问题,因此,需要了解Cookies操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 In [100 ]: browser.get('https://www.baidu.com' ) In [101 ]: browser.get_cookies() Out[101 ]: [{'domain' : '.baidu.com' , 'httpOnly' : False , 'name' : 'H_PS_PSSID' , 'path' : '/' , 'secure' : False , 'value' : '1426_21117_26350_26433_22075' }, {'domain' : '.baidu.com' , 'expiry' : 3677830659.441811 , 'httpOnly' : False , 'name' : 'BIDUPSID' , 'path' : '/' , 'secure' : False , 'value' : 'C914BFBE505CBD0F56D8C9E95B71AF50' }, {'domain' : '.baidu.com' , 'expiry' : 3677830659.441852 , 'httpOnly' : False , 'name' : 'PSTM' , 'path' : '/' , 'secure' : False , 'value' : '1530347012' }, {'domain' : '.baidu.com' , 'expiry' : 1530433417.192771 , 'httpOnly' : False , 'name' : 'BDORZ' , 'path' : '/' , 'secure' : False , 'value' : 'B490B5EBF6F3CD402E515D22BCDA1598' }, {'domain' : 'www.baidu.com' , 'expiry' : 1531211072 , 'httpOnly' : False , 'name' : 'BD_UPN' , 'path' : '/' , 'secure' : False , 'value' : '123253' }, {'domain' : 'www.baidu.com' , 'httpOnly' : False , 'name' : 'BD_HOME' , 'path' : '/' , 'secure' : False , 'value' : '0' }, {'domain' : '.baidu.com' , 'expiry' : 3677830659.441722 , 'httpOnly' : False , 'name' : 'BAIDUID' , 'path' : '/' , 'secure' : False , 'value' : 'C914BFBE505CBD0F56D8C9E95B71AF50:FG=1' }] In [102 ]: browser.add_cookie(cookie_dict=browser.get_cookies()[-1 ])
滚动条操作 一些页面是动态加载,只有当页面展示给用户可见的时候,才会加载相应的数据。例如,京东商品页面信息,向下滚动的时候才会请求另外30个item。因此,就需要操作浏览器滚动条,滚动到底部,让所有的信息都加载出来。
我们在ipython中使用一下滚动条的操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 In [119 ]: browser = webdriver.Chrome() In [120 ]: browser.get('https://www.jd.com' ) In [121 ]: ele_search = browser.find_element_by_id('key' ) In [122 ]: ele_submit = browser.find_element_by_class_name('button' ) In [123 ]: ele_search.send_keys('书包' ) In [124 ]: ele_submit.click() In [125 ]: from bs4 import BeautifulSoup In [126 ]: soup = BeautifulSoup(browser.page_source,'lxml' ) In [127 ]: len(soup.findAll('li' ,class_='gl-item' )) Out[127 ]: 30 In [128 ]: browser.execute_script('window.scrollTo(0, document.body.scrollHeight)' ) In [129 ]: soup = BeautifulSoup(browser.page_source,'lxml' ) In [130 ]: len(soup.findAll('li' ,class_='gl-item' )) Out[130 ]: 60
等待页面加载完成(Waits) 现在我们在互联网上遇到的网站大多都会使用动态加载页面,因此,对我们的爬虫造成一定的干扰。页面中的元素或者内容,可以在不同的时间动态加载,这使得定位元素变得困难,例如前面的京东实战,60个页面item中有30个是后台动态请求服务器进行加载后渲染的。如果我们在定位元素的时候,元素还未被加载出来,那么将会ElementNotVisibleException异常。
使用Waits来等待页面完整加载出来,就可以解决该问题。
Selenium WebDriver提供两种类型的waits,即隐式waits 和显式waits 。
它们之间的区别是,隐式等待是让WebDriver等待一段时间后再查找元素;显式等待是让WebDriver等待满足某一条件后再进行下一步的操作。
显式等待 WebDriverWait结合ExpectedCondition是一种比较好用的方式。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 from selenium import webdriverfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECdriver = webdriver.Chrome() driver.get("http://somedomain/url_that_delays_loading" ) try : element = WebDriverWait(driver, 10 ).until( EC.presence_of_element_located((By.ID, "myDynamicElement" )) ) finally : driver.quit()
在请求没有超时的情况下,等待10秒或者在10秒内发现了查找的元素。WebDriverWait 默认情况下会每500毫秒调用一次ExpectedCondition直到结果成功返回。 ExpectedCondition成功的返回结果是一个布尔类型的true或是不为null的返回值。
常用预期条件如下:
预期条件
含义
title_is
判断当前页面的title是否等于预期
title_contains
判断当前页面的title是否包含预期字符串
presence_of_element_located
判断某个元素是否被加到了dom树里,并不代表该元素一定可见
visibility_of_element_located
判断某个元素是否可见. 可见代表元素非隐藏,并且元素的宽和高都不等于0
visibility_of
跟上面的方法做一样的事情,只是上面的方法要传入locator,这个方法直接传定位到的element就好了
presence_of_all_elements_located
判断是否至少有1个元素存在于dom树中。举个例子,如果页面上有n个元素的class都是’column-md-3’,那么只要有1个元素存在,这个方法就返回True
text_to_be_present_in_element
判断某个元素中的text是否包含了预期的字符串
text_to_be_present_in_element_value
判断某个元素中的value属性是否包含了预期的字符串
frame_to_be_available_and_switch_to_it
判断该frame是否可以switch进去,如果可以的话,返回True并且switch进去,否则返回False
invisibility_of_element_located
判断某个元素中是否不存在于dom树或不可见
element_to_be_clickable
判断某个元素中是否可见并且是enable的,这样的话才叫clickable
staleness_of
等某个元素从dom树中移除,注意,这个方法也是返回True或False
element_to_be_selected
判断某个元素是否被选中了,一般用在下拉列表
element_located_to_be_selected
跟上面的方法作用一样,只是上面的方法传入定位到的element,而这个方法传入locator
element_selection_state_to_be
判断某个元素的选中状态是否符合预期
element_located_selection_state_to_be
跟上面的方法作用一样,只是上面的方法传入定位到的element,而这个方法传入locator
alert_is_present
判断页面上是否存在alert
隐式等待 如果某些元素不是立即可用的,隐式等待是告诉WebDriver去等待一定的时间后去查找元素。 默认等待时间是0秒,一旦设置该值,隐式等待是设置该WebDriver的实例的生命周期。
示例代码:
1 2 3 4 5 6 from selenium import webdriverdriver = webdriver.Firefox() driver.implicitly_wait(10 ) driver.get("http://somedomain/url_that_delays_loading" ) myDynamicElement = driver.find_element_by_id("myDynamicElement" )
PhantomJS无头浏览器的用法 其实PhantomJS在爬虫中的应用非常简单,只需用WebDriver驱动PhantomJS即可,回到ipython环境中:
1 2 3 4 5 6 7 8 In [143 ]: browser = webdriver.PhantomJS() /Users/sunjiajia/Works/pyenv/crawler/lib/python3.6 /site-packages/selenium/webdriver/phantomjs/webdriver.py:49 : UserWarning: Selenium support for PhantomJS has been deprecated, please use headless versions of Chrome or Firefox instead warnings.warn('Selenium support for PhantomJS has been deprecated, please use headless ' In [146 ]: browser.get('https://www.baidu.com' ) In [148 ]: browser.page_source[:1000 ] Out[148 ]: '<!DOCTYPE html><!--STATUS OK--><html><head>\n \n <meta http-equiv="content-type" content="text/html;charset=utf-8">\n <meta http-equiv="X-UA-Compatible" content="IE=Edge">\n\t<meta content="always" name="referrer">\n <meta name="theme-color" content="#2932e1">\n <link rel="shortcut icon" href="/favicon.ico" type="image/x-icon">\n <link rel="search" type="application/opensearchdescription+xml" href="/content-search.xml" title="百度搜索">\n <link rel="icon" sizes="any" mask="" href="//www.baidu.com/img/baidu_85beaf5496f291521eb75ba38eacbd87.svg">\n\t\n\t\n\t<link rel="dns-prefetch" href="//s1.bdstatic.com">\n\t<link rel="dns-prefetch" href="//t1.baidu.com">\n\t<link rel="dns-prefetch" href="//t2.baidu.com">\n\t<link rel="dns-prefetch" href="//t3.baidu.com">\n\t<link rel="dns-prefetch" href="//t10.baidu.com">\n\t<link rel="dns-prefetch" href="//t11.baidu.com">\n\t<link rel="dns-prefetch" href="//t12.baidu.com">\n\t<link rel="dns-prefetch" href="//b1.bdstatic.com">\n \n <title>百度一下,你就知道</title>\n '
ヽ(^o^)丿这是什么鬼?竟然提示Selenium已经废弃了对PhantomJS的支持,但,还是获取到了信息。讲到这里了都,瑟瑟发抖中。。
于是,再加一个小章节,说明解决这个问题的方法。
headless Chrome的用法 Selenium WebDriver已经通知我们,将废弃对PhantomJS的支持,那么,我们来使用一下headless Chrome吧。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 In [1 ]: from selenium import webdriver In [2 ]: from selenium.webdriver.chrome.options import Options as ChromeOptions In [3 ]: chrome_options = ChromeOptions() In [4 ]: chrome_options.add_argument('--headless' ) In [5 ]: chrome_options.add_argument('--disable-gpu' ) In [6 ]: browser = webdriver.Chrome(chrome_options=chrome_options) In [7 ]: browser.get('https://www.baidu.com' ) In [8 ]: browser.page_source[:1000 ] Out[8 ]: '<!DOCTYPE html><!--STATUS OK--><html xmlns="http://www.w3.org/1999/xhtml"><head>\n \n <meta http-equiv="content-type" content="text/html;charset=utf-8" />\n <meta http-equiv="X-UA-Compatible" content="IE=Edge" />\n\t<meta content="always" name="referrer" />\n <meta name="theme-color" content="#2932e1" />\n <link rel="shortcut icon" href="/favicon.ico" type="image/x-icon" />\n <link rel="search" type="application/opensearchdescription+xml" href="/content-search.xml" title="百度搜索" />\n <link rel="icon" sizes="any" mask="" href="//www.baidu.com/img/baidu_85beaf5496f291521eb75ba38eacbd87.svg" />\n\t\n\t\n\t<link rel="dns-prefetch" href="//s1.bdstatic.com" />\n\t<link rel="dns-prefetch" href="//t1.baidu.com" />\n\t<link rel="dns-prefetch" href="//t2.baidu.com" />\n\t<link rel="dns-prefetch" href="//t3.baidu.com" />\n\t<link rel="dns-prefetch" href="//t10.baidu.com" />\n\t<link rel="dns-prefetch" href="//t11.baidu.com" />\n\t<link rel="dns-prefetch" href="//t12.baidu.com" />\n\t<link rel="dns-prefetc'
headless Firefox的用法 在ipython中测试headless Firefox的用法,其实和headless Chrome的用法基本一致:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 In [1 ]: from selenium import webdriver In [2 ]: from selenium.webdriver.firefox.options import Options as FFOptions In [3 ]: ff_options = FFOptions() In [4 ]: ff_options.add_argument('--headless' ) In [5 ]: browser = webdriver.Firefox(firefox_options=ff_options) In [7 ]: browser.get("https://www.baidu.com" ) In [9 ]: browser.page_source[:1000 ] Out[9 ]: '<html><head>\n \n <meta http-equiv="content-type" content="text/html;charset=utf-8">\n <meta http-equiv="X-UA-Compatible" content="IE=Edge">\n\t<meta content="always" name="referrer">\n <meta name="theme-color" content="#2932e1">\n <link rel="shortcut icon" href="/favicon.ico" type="image/x-icon">\n <link rel="search" type="application/opensearchdescription+xml" href="/content-search.xml" title="百度搜索">\n <link rel="icon" sizes="any" mask="" href="//www.baidu.com/img/baidu_85beaf5496f291521eb75ba38eacbd87.svg">\n\t\n\t\n\t<link rel="dns-prefetch" href="//s1.bdstatic.com">\n\t<link rel="dns-prefetch" href="//t1.baidu.com">\n\t<link rel="dns-prefetch" href="//t2.baidu.com">\n\t<link rel="dns-prefetch" href="//t3.baidu.com">\n\t<link rel="dns-prefetch" href="//t10.baidu.com">\n\t<link rel="dns-prefetch" href="//t11.baidu.com">\n\t<link rel="dns-prefetch" href="//t12.baidu.com">\n\t<link rel="dns-prefetch" href="//b1.bdstatic.com">\n \n <title>百度一下,你就知道</title>\n \n\n<style id="css_index" index'
Selenium WebDriver的常用方法总结 浏览器常用功能操作
用法
含义
browser.maximize_window()
浏览器最大化
browser.set_window_size(480, 800)
设置浏览器的宽高
browser.back()
浏览器后退
browser.forward()
浏览器前进
browser.quit()
浏览器退出
browser.title
浏览器标题
browser.current_url
浏览器当前网址
对象定位操作
方法名
含义
browser.find_element_by_id()
根据标签的id属性值查找
browser.find_element_by_name()
根据标签的name属性值查找,当有多个时,返回第1个
browser.find_element_by_class_name()
根据标签的class属性值查找,当有多个时,返回第1个
browser.find_element_by_tag_name()
根据标签名值查找
browser.find_element_by_link_text()
根据标签的文字链接查找
browser.find_element_by_partial_link_text()
根据标签的文字链接模糊查找
browser.find_element_by_xpath()
根据xpath表达式进行匹配查找
browser.find_element_by_css_selector()
根据css表达式进行匹配查找
另外,还有一系列的browser.find_elements_by_**方法,它们是对应的复数形式,返回的是列表,列表中存储的是selenium.webdriver.remote.webelement.WebElement类型。
元素操作
方法
含义
element.clear()
如果可以的话,清除元素的内容
element.send_keys()
在元素上模拟按键输入
element.click()
单击元素
element.submit()
表单提交
键盘操作 send_keys()可用Keys类来模拟键盘操作,常用的操作有:
操作名
含义
send_keys(Keys.BACK_SPACE)
删除键(BackSpace)
send_keys(Keys.SPACE)
空格键(Space)
send_keys(Keys.TAB)
制表键(Tab)
send_keys(Keys.ESCAPE)
回退键(Esc)
send_keys(Keys.ENTER)
回车键(Enter)
send_keys(Keys.CONTROL,’a’)
全选(Ctrl+A)
send_keys(Keys.CONTROL,’c’)
复制(Ctrl+C)
send_keys(Keys.CONTROL,’x’)
剪切(Ctrl+X)
send_keys(Keys.CONTROL,’v’)
粘贴(Ctrl+V)
浏览器多窗口
属性
含义
browser.current_window_handle
获得当前窗口
browser.window_handles
获取全部窗口
browser.window_handles[1]
获取第2个窗口
browser.switch_to_window(driver.window_handles[1])
切换到第2个窗口
browser.close()
关闭窗口
Cookie处理
方法名
含义
get_cookies()
获得所有cookie 信息
get_cookie(name)
返回特定name 有cookie 信息
add_cookie(cookie_dict)
添加cookie,必须有name 和value 值
delete_cookie(name)
删除特定(部分)的cookie 信息
delete_all_cookies()
删除所有cookie 信息
示例:
1 2 3 4 5 6 7 driver.get("http://www.xxxx.com/" ) driver.add_cookie({'name' :'username' , 'value' :'gitopen' }) driver.add_cookie({'name' :'password' , 'value' :'123456' }) driver.get("http://www.xxxx.com/" )
实战——用Selenium爬取腾讯招聘信息 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 from selenium import webdriverfrom selenium.webdriver.chrome.options import Optionsfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECfrom selenium.webdriver.common.by import Byfrom bs4 import BeautifulSoupimport timeimport jsonchrome_options = Options() chrome_options.add_argument('--headless' ) chrome_options.add_argument('--diable-gpu' ) browser = webdriver.Chrome(chrome_options=chrome_options) browser.get("https://hr.tencent.com/position.php?&start=0#a" ) result = [] while True : job = {} try : element = WebDriverWait(browser, 10 ).until( EC.presence_of_all_elements_located((By.ID, 'next' )) ) except Exception as e: print(str(e)) browser.execute_script('window.scrollTo(0, document.body.scrollHeight)' ) print("## 正在爬取连接:{}" .format(browser.current_url)) soup = BeautifulSoup(browser.page_source, 'lxml' ) tag_table = soup.find('table' ) tr_even = tag_table.find_all('tr' , {'class' : 'even' }) tr_odd = tag_table.find_all('tr' , {'class' : 'odd' }) for tr in tr_even + tr_odd: tds = tr.find_all('td' ) job['url' ] = "https://hr.tencent.com/" + tds[0 ].a.attrs['href' ] job['title' ] = tds[0 ].a.string job['level' ] = tds[1 ].string if tds[1 ].string is not None else "" job['num' ] = tds[2 ].string job['location' ] = tds[3 ].string job['date' ] = tds[4 ].string result.append(job) a_next = soup.find(id='next' ) if 'class' in a_next.attrs.keys() and a_next.attrs['class' ][0 ] == 'noactive' : break else : ele_next = browser.find_element_by_id('next' ) ele_next.click() localtime = "-" .join(time.asctime(time.localtime(time.time())).split(' ' )) with open("job_" + localtime + '.json' , 'w' ) as filename: filename.write(json.dumps(result, ensure_ascii=False )) print("### 爬取完毕" )
参考资料 《Selenium with Python中文翻译文档》