
本教程所有源码下载链接:https://share.weiyun.com/5xmFeUO 密码:fzwh6g
Requests库讲解
简介与安装
Requests是一常用的http请求库,它使用python语言编写,可以方便地发送http请求,以及方便地处理响应结果。
引用官方文档中的第一句话,来对Requests库进行一句话简介:
Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用。
翻译一下,就是:
Requests库使用简单安全,威力无边,老少皆宜。
至于安装,使用pip安装,简直不能更方便了:
1 | pip install requests |
其他不多说,直接上手!
Requests库的基本用法
体验入门
通过用一个读取百度首页的例子,来体验一下如何在不用浏览器的情况下,读取互联网上的信息。
1 | import requests |
多次运行程序,控制台下输出的结果有两种,并且在当前文件夹下生成了一个baidu.html的文件,保存了从互联网上读取来的百度首页的内容:
1 | # HTTP请求状态码 |
1 | 200 |
输出的结果有两种,是因为每一次服务器都给Requests发送的请求回应了不同的响应信息。这点不重要,这个现象是为了后面讨论response.encoding的用法。
入门例子剖析
HTTP状态码
当你需要访问一个网页时,你的浏览器(这里是Requests库)向网页所在的服务器(百度服务器)发出请求;服务器会返回一个头信息(server header),用以响应浏览器的请求。
常用HTTP请求状态码含义:
| 状态码 | 含义 |
|---|---|
| 200 | 请求成功 |
| 301 | 资源被永久转移到其它URL |
| 404 | 请求的资源不存在 |
| 505 | 内部服务器错误 |
这些状态码的含义不必死记硬背,可以在需要的时候搜索一下。这里方便参考,给出简记方法:
| 非正常状态码 | 简记 |
|---|---|
| 1xx | 服务器对客户端说:收到了 |
| 2xx | 服务器对客户端说:合作愉快 |
| 3xx | 服务器对客户端说:回头见 |
| 4xx | 服务器对客户端说:你错了 |
| 5xx | 服务器对客户端说:我错了 |
更详细的有关用法,只在有需求的时候查阅就可以了。参见《HTTP状态码》。
网页编码
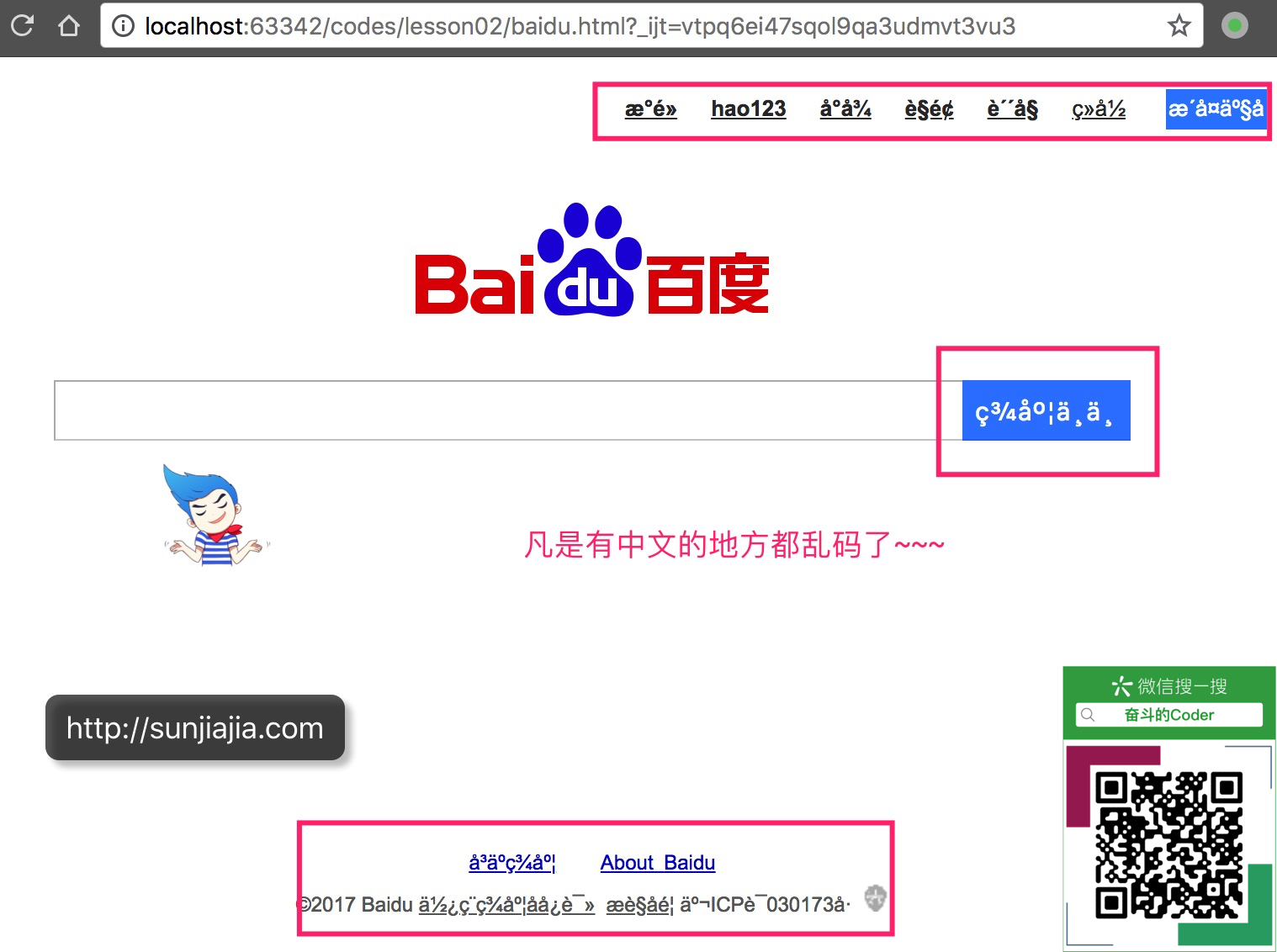
当得到的网页编码是ISO-8859-1时,我们在浏览器中打开baidu.html文件,发现是页面中凡是中文的地方都是乱码,如图:
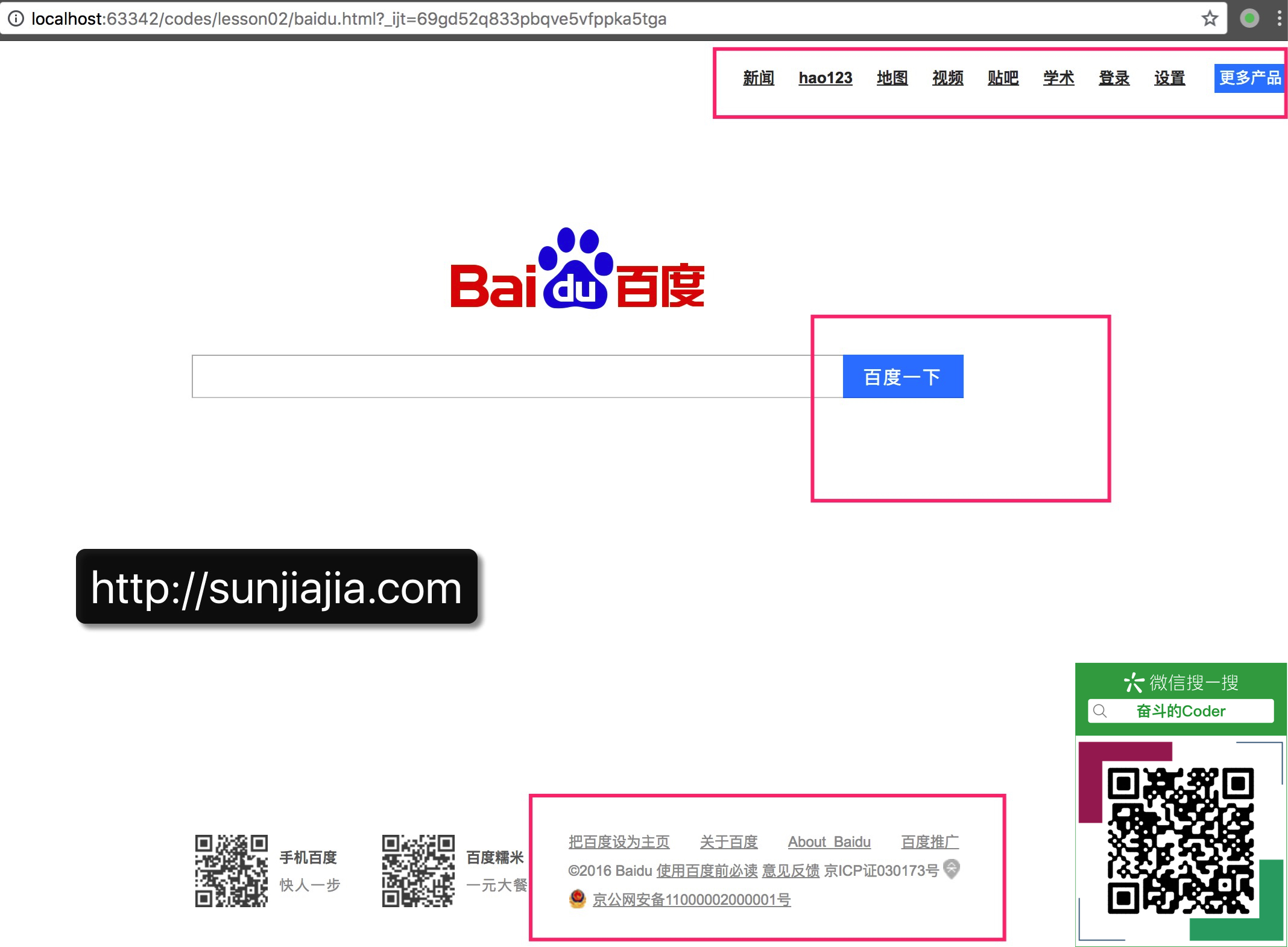
当得到的网页编码是utf-8时,我们在浏览器中打开baidu.html文件,发现是页面是正常的,如图:
总结:
- 当headers中不存在charset时,
response.encoding默认认为编码为ISO-8859-1 - 当headers中存在charset时,
response.encoding显示为headers中charset的编码
头信息
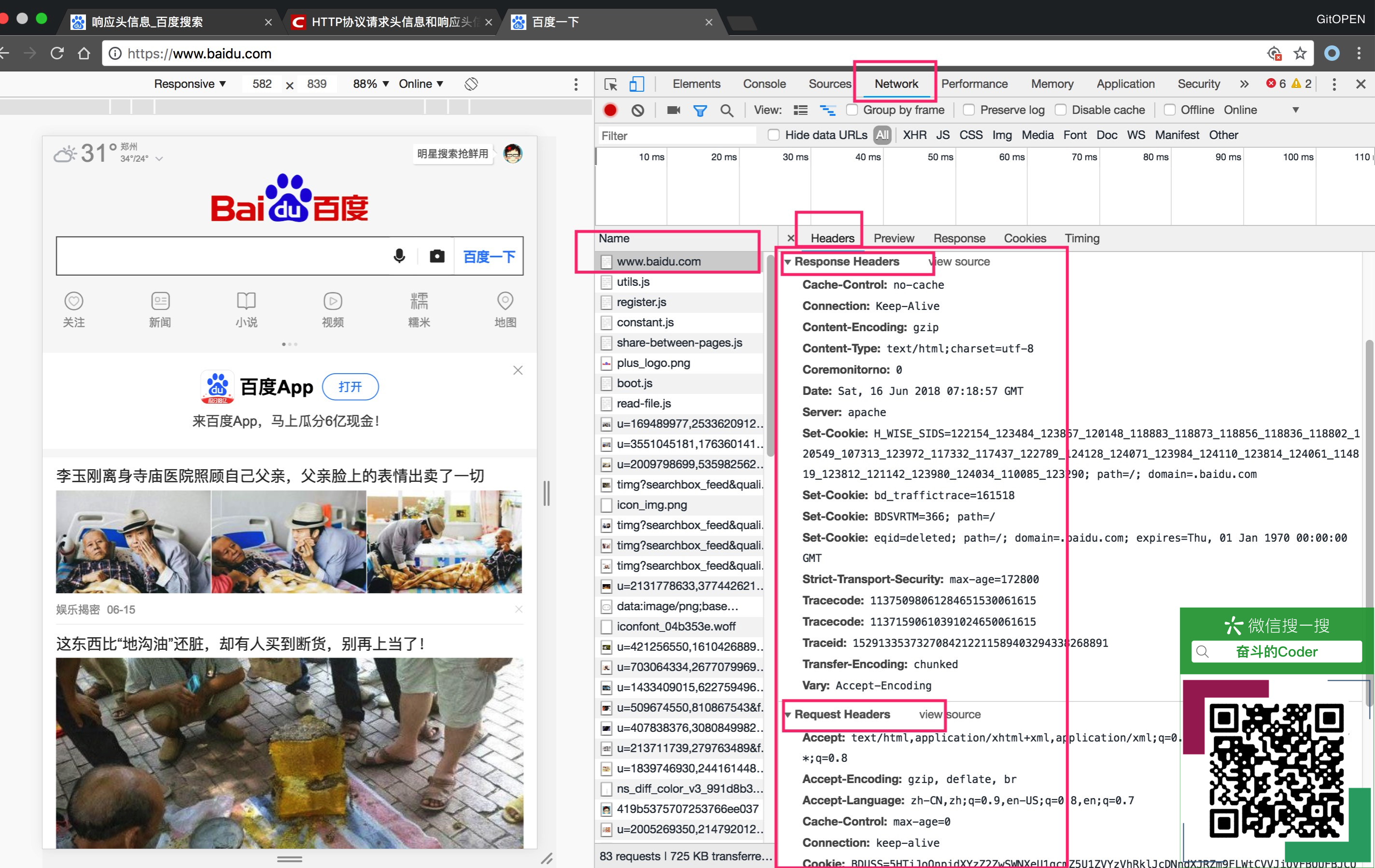
浏览器在与服务器进行交流的过程中,会协商一些参数,用于影响页面的渲染和展示。当浏览器向服务器发送请求的时候,所携带的信息为请求头信息;当服务器向浏览器返回响应信息的时候,携带的信息响应头信息。在浏览器中,我们可以直观的看到这些信息:
这里我们不做详细的讲解,有兴趣的同学可以参考《HTTP教程》。
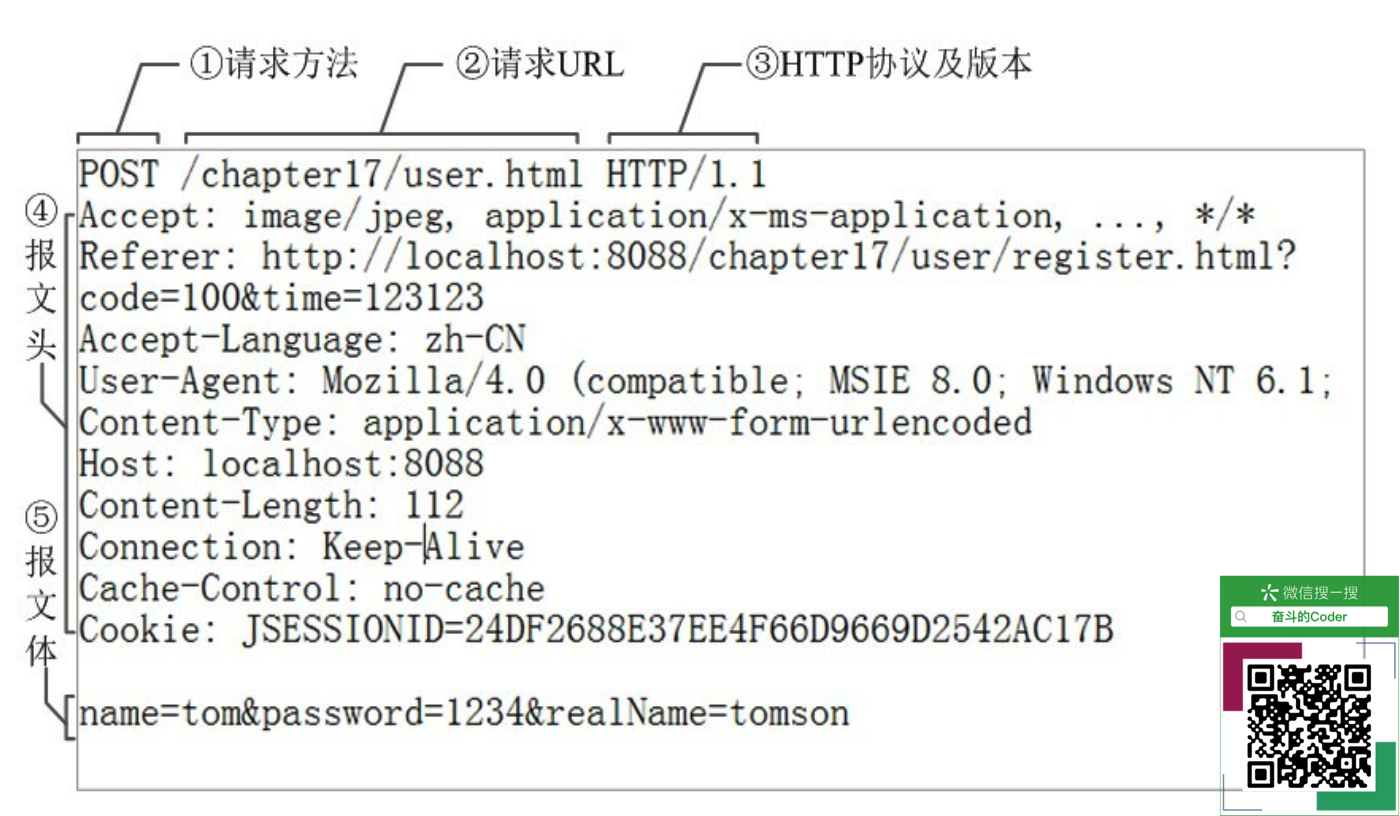
HTTP请求报文(了解)
HTTP请求报文由3部分组成:请求行+请求头+请求体
获取请求报文的方法(Chrome浏览器)如图所示:
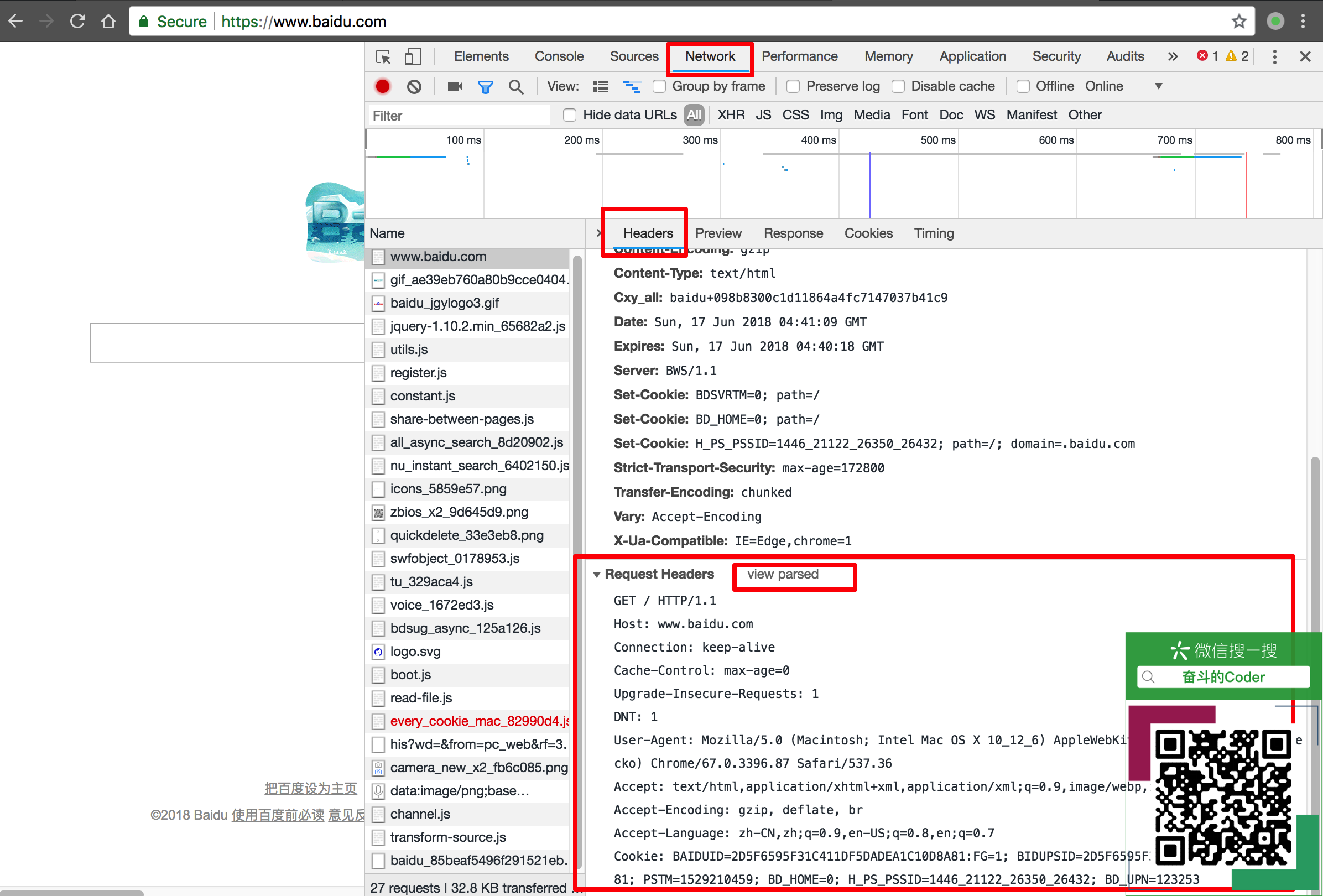
Request Headers的内容如下:
1 | GET / HTTP/1.1 |
图解为:
Requests库也可以帮助我们拿到这些信息,以下代码在ipython中进行。
1 | In [20]: r = requests.post('http://httpbin.org/post', data = {'username':'zhangsan','password':'123456'}) |
Request Headers的字段讲解:
| 属性名 | 含义 |
|---|---|
| Accept | 请求报文通过该属性告诉服务端,客户端接受什么类型的响应 |
| Cookie | HTTP请求发送时,会把保存在该请求域名下的所有cookie值一起发送给web服务器 |
| Referer | 先前网页的地址,当前请求网页紧随其后,即来路 |
| Cache-Control | 指定请求和响应遵循的缓存机制 |
| Connection | 表示是否需要持久连接(HTTP 1.1默认进行持久连接) |
| Upgrade-Insecure-Requests | 让浏览器自动升级请求 (由 http 升级成 https) |
| User-Agent | 浏览器的浏览器身份标识字符串 |
| Accept-Encoding | 能够接受的编码方式列表 |
| Accept-Language | 能够接受的回应内容的自然语言列表 |
| Accept-Charset | 能够接受的字符集 |
更多具体的请求字段含义,请参考维基HTTP头字段,这里不做详细讲解。
HTTP协议
HTTP协议可是互联网最基础最重要的协议。它可是一门大的学问。我们这里仅仅讲解一些基本概念。
HTTP协议,超文本传输协议,即HyperText Transfer Protocol,是互联网上应用最为广泛的一种网络协议。所有的WWW文件都必须遵守这个标准。
HTTP是一个基于“请求与响应”模式的、无状态的应用层协议。无状态可以理解为:每一个请求与响应没有上下文联系。
对于HTTP协议,我们在日常使用过程中,最直观的就是URL,即统一资源定位符。它的格式为:http://host[:port][path]。URL是通过HTTP协议存取互联网资源的路径,一个URL对应一个数据资源。
HTTP协议的请求方法,常用的有6种,Requests的几个常用方法是和这个对应的:
| 方法名 | 含义 |
|---|---|
| GET | 请求获取URL位置的资源 |
| POST | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件) |
| HEAD | 向服务器请求与GET请求相一致的响应,只不过响应体将不会被返回。这一方法可以再不必传输整个响应内容的情况下,就可以获取包含在响应小消息头中的元信息。 |
| PUT | 向指定资源位置上传其最新内容,覆盖原资源 |
| DELETE | 请求服务器删除URL定位的资源 |
| PATCH | 请求局部更新URL定位的资源,节省网络带宽 |
Requests库常用方法入门
需要知道的7个方法:
| 方法名称 | 意义 |
|---|---|
| requests.request() | 构造一个请求。它是基础方法 |
| requests.get() | 发送Get请求获取网页信息, 并返回实体主体,也可以提交数据,包含在url中 |
| requests.post() | 向指定资源提交数据进行处理请求(提交表单或者上传文件),数据被包含在请求体中 |
| requests.head() | 类似于get请求,返回的响应中没有具体的内容,用于获取报头 |
| requests.put() | 发送PUT请求的方法, 从客户端向服务器传送的数据取代指定的文档的内容。 |
| requests.patch() | 发送PATCH(局部修改)请求的方法 |
| requests.delete() | 发送DELETE(删除)请求的方法, 请求服务器删除指定的资源 |
在实际编写爬虫的时候,最最常用的也就是加粗显示的3个方法。下面,我们在ipython中测试使用这几个方法。
requests.head()使用方法
获取响应头信息,没有返回内容体。
1 | $ ipython |
requests.post()
向URL用POST请求发送一个字典,自动编码为form表单数据。
1 | In [4]: payload = {'key1': 'value1','key2': 'value2'} |
form字段:
1 | "form":{"key1":"value1","key2":"value2"} |
向URL用POST请求发送一个字符串,自动编码为data。
1 | In [7]: abc = 'ABC' |
data字段:
1 | "data":"ABC" |
requests.put()
该方法和post()方法的使用类似,只不过它可以将原有的数据覆盖掉。
Requests库主要方法解析
requests.request(method,url,**kwargs)
- method:请求方式,对应get/put/post等7种
- url:获取页面的url连接
- kwargs:控制访问的参数,共13个,均为可选项
因此,将method改为不同的请求方式,将等同于具体的requests请求方法。
例如:`requests.request(“GET”,url,kwargs)等同于requests.get(url,kwargs)`。 kwargs:控制访问的参数,13个可用参数的具体使用方法如下:
params:字典或者字节序列,作为参数增加到url中
1
2
3
4
5
6In [10]: kv = {'key1': 'value1','key2': 'value2'}
In [11]: r = requests.request('GET','http://python123.io/ws', params = kv)
In [12]: print(r.url)
https://python123.io/ws?key1=value1&key2=value2data:字典、字节序列或者文件对象,作为Request的内容。
1
2
3
4
5
6
7In [21]: kv = {'key1': 'value1','key2': 'value2'}
In [22]: r = requests.request('POST','http://python123.io/ws', data = kv)
In [23]: body = '主体内容'
In [24]: r = requests.request('POST','http://python123.io/ws', data = body.encode('utf-8'))json:JSON格式的数据,作为Request的内容。
1
2
3ln [25]: kv = {'key1': 'value1','key2': 'value2'}
In [26]: r = requests.request('POST','http://python123.io/ws', json = kv)headers:字典,用来指定请求头。⭐️
1
2
3In [27]: hd = {'User-Agent': 'Chrome/10'}
In [28]: r = requests.request('POST','http://python123.io/ws', headers = hd)cookies:字典或者CookieJar,Request中的cookie。⭐️
auth:元祖,支持HTTP认证功能。
files:字典类型,传输文件。
1
2
3In [35]: fs = {'file': open('baidu.html','rb')}
In [36]: r = requests.request('POST','http://python123.io/ws', files = fs)timeout:设定超时时间,单位,秒。⭐️
1
In [37]: r = requests.request('GET','http://python123.io/ws', timeout = 10)
proxies:字典类型,设定访问代理服务器,可以增加登录认证。⭐️
使用这个字段,可以隐藏自己的ip,防止服务器识别爬虫。
1
2
3
4
5In [40]: pxs = {
...: 'http': 'http://user:pass@10.10.10.10:1234',
...: 'https': 'https://10.10.10.10:4321'}
In [41]: r = requests.request('GET', 'http://www.baidu.com', proxies = pxs)allow_redirects:它的值为True/False,默认为True,重定向开关。表示,是否允许对url进行重定向。
stream:True/False,默认值为True,获取的内容是否立即下载。默认是立即下载的。
verify:True/False,默认为True,认证SSL证书开关。是否对SSL证书进行认证。
cert:本地SSL证书路径。
Response对象的属性
需要记住的几个属性为:
| 属性名 | 含义 |
|---|---|
| response.status_code | HTTP响应状态码 |
| response.encoding | 从HTTP中charset推断的网页编码方式,如果charset不存在,返回ISO-8859-1 |
| response.apparent_encoding | 从响应内容中分析出的内容编码方式 |
| response.content | 二进制形式的响应内容,如请求的连接是一个图片等二进制文件,返回的内容用response.content |
| response.text | 字符串形式的响应内容,如请求的连接是一个网页,其内容为html等字符串形式内容,返回的内容用response.text |
在爬虫实践中,如果是反复循环迭代大量信息,不建议使用response.apparent_encoding来推断网页编码,因为这个操作非常耗时。因此,通常的做法是,我们在编写爬虫时,提前确定网页的编码方式,然后设置给response.encoding。
Requests库的异常
| 异常 | 含义 |
|---|---|
| requests.ConnectionError | 网络连接出现异常,如拒绝连接等 |
| requests.HTTPError | HTTP错误异常 |
| requests.URLRequired | URL缺失异常 |
| requests.TooManyRedirects | 请求超过了设定的最大重定向次数 |
| requests.ConnectTimeout | 连接远程服务器超时异常 |
| requests.Timeout | 请求URL超时,产生超时异常 |
动手试一试:
在下面的通用代码中,用Exception这个父类,捕捉了所有可能出现的异常。如果将url = "http://www.baidu.com"中的网址写错了,例如将http://去掉,将会报错requests.exceptions.MissingSchema:
1 | 出现异常,类型为:<class 'requests.exceptions.MissingSchema'>,内容为:Invalid URL 'www.baidu.com': No schema supplied. Perhaps you meant http://www.baidu.com? |
爬取网页的通用代码示例
1 | import requests |
实战——获取京东商品页面信息
该实验在ipython下进行。
1 | In [1]: import requests |
实战——爬取网络图片并存储在本地
该实验在pycharm编辑器中编写并执行:
1 | import requests |
参考资料推荐
- Requests官方文档:《Requests: HTTP for Humans》


