# 导入 Beautiful Soup 4 In [1]: from bs4 import BeautifulSoup # 导入 requests In [2]: import requests # get请求网页 In [3]: r = requests.get("https://raw.githubusercontent.com/opengit/CrawlerLessons/master/codes/lesson03/bs4_demo01.html")
# html文本内容 In [4]: demo = r.text # 拿到BeautifulSoup的对象 In [5]: soup = BeautifulSoup(demo, "html.parser") # 获取a标签的名称 In [6]: soup.a.name Out[6]: 'a' # 获取a标签的父标签的名字 In [7]: soup.a.parent.name Out[7]: 'p' # 获取a标签的父标签的父标签的名字 In [8]: soup.a.parent.parent.name Out[8]: 'body' # soup.a的类型是Tag In [9]: tag = soup.a # 类型为Tag的a标签的属性 In [10]: tag.attrs Out[10]: {'href': 'https://m.do.co/c/fd128f8ba9e8', 'class': ['vps1'], 'id': 'link1'} # 取标签的属性值 In [11]: tag.attrs['class'] Out[11]: ['vps1'] In [12]: tag.attrs['href'] Out[12]: 'https://m.do.co/c/fd128f8ba9e8' # Tag的属性返回的是一个字典类型 In [13]: type(tag.attrs) Out[13]: dict # soup.a 是一个Tag类型 In [14]: type(tag) Out[14]: bs4.element.Tag In [15]: tag Out[15]: <a class="vps1" href="https://m.do.co/c/fd128f8ba9e8" id="link1">Digital Ocean优惠链接</a> # 标签中的字符串 In [16]: tag.string Out[16]: 'Digital Ocean优惠链接' In [17]: soup.p Out[17]: <p class="title"> <b>亲测速度很快</b> </p> In [18]: soup.p.string In [19]: soup.p.b.string Out[19]: '亲测速度很快' In [20]: type(soup.p.b.string) # 标签中的字符串是NavigableString类型 Out[20]: bs4.element.NavigableString
# Comment 示例 In [25]: newsoup = BeautifulSoup("<b><!--我是注释--></b><p>我是注释</p>","html.parser") In [26]: newsoup.b.string Out[26]: '我是注释' In [27]: type(newsoup.b.string) Out[27]: bs4.element.Comment In [29]: newsoup.p.string Out[29]: '我是注释' In [30]: type(newsoup.p.string) Out[30]: bs4.element.NavigableString
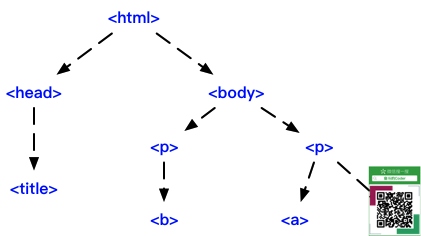
In [33]: r = requests.get("https://raw.githubusercontent.com/opengit/CrawlerLessons/master/codes/lesson03/bs4_demo01.html") In [34]: demo = r.text In [35]: soup = BeautifulSoup(demo, "html.parser") In [36]: soup.head Out[36]: <head><meta content="text/html; charset=utf-8" http-equiv="Content-Type"/><title>VPS推荐</title></head>
# head标签的子节点列表 In [37]: soup.head.contents Out[37]: [<meta content="text/html; charset=utf-8" http-equiv="Content-Type"/>, <title>VPS推荐</title>] # body标签的子节点列表 In [38]: body = soup.body.contents In [39]: body Out[39]: [<p class="title"><b>亲测速度很快</b></p>, <p class="links">下面是两个推荐的VPS服务器链接:<a class="vps1" href="https://m.do.co/c/fd128f8ba9e8" id="link1">Digital Ocean优惠链接</a> 和<a class="vps2" href="https://www.vultr.com/?ref=7147564" id="link2">Vultr优惠10美元链接</a>。</p>]
# body标签的子节点列表的长度 In [40]: len(body) Out[40]: 2
# body的所有子孙节点的迭代类型generator In [41]: bodys = soup.body.descendants In [42]: bodys Out[42]: <generator object descendants at 0x104e2c0a0> # 遍历子孙节点 In [43]: for item in bodys: ...: print(item) ...: <p class="title"><b>亲测速度很快</b></p> <b>亲测速度很快</b> 亲测速度很快 <p class="links">下面是两个推荐的VPS服务器链接:<a class="vps1" href="https://m.do.co/c/fd128f8ba9e8" id="link1">Digital Ocean优惠链接</a> 和<a class="vps2" href="https://www.vultr.com/?ref=7147564" id="link2">Vultr优惠10美元链接</a>。</p> 下面是两个推荐的VPS服务器链接: <a class="vps1" href="https://m.do.co/c/fd128f8ba9e8" id="link1">Digital Ocean优惠链接</a> Digital Ocean优惠链接 和 <a class="vps2" href="https://www.vultr.com/?ref=7147564" id="link2">Vultr优惠10美元链接</a> Vultr优惠10美元链接 。 # body标签的子节点迭代类型 In [44]: bodyc = soup.body.children # 遍历 In [45]: for item in bodyc: ...: print(item) ...: <p class="title"><b>亲测速度很快</b></p> <p class="links">下面是两个推荐的VPS服务器链接:<a class="vps1" href="https://m.do.co/c/fd128f8ba9e8" id="link1">Digital Ocean优惠链接</a> 和<a class="vps2" href="https://www.vultr.com/?ref=7147564" id="link2">Vultr优惠10美元链接</a>。</p>
上行遍历
标签树从下往上进行遍历。上行遍历的几个属性:
属性
含义
.parent
<tag>的父亲标签
.parents
<tag>的先辈们标签的迭代类型,用于遍历循环
接着上面的例子,下面在ipython中进行测试:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
In [46]: soup.title.parent Out[46]: <head><meta content="text/html; charset=utf-8" http-equiv="Content-Type"/><title>VPS推荐</title></head> # 由于html标签是最外层标签,因此html标签的父标签是它自己 In [47]: soup.html.parent Out[47]: <!DOCTYPE html>
<html><head><meta content="text/html; charset=utf-8" http-equiv="Content-Type"/><title>VPS推荐</title></head><body><p class="title"><b>亲测速度很快</b></p><p class="links">下面是两个推荐的VPS服务器链接:<a class="vps1" href="https://m.do.co/c/fd128f8ba9e8" id="link1">Digital Ocean优惠链接</a> 和<a class="vps2" href="https://www.vultr.com/?ref=7147564" id="link2">Vultr优惠10美元链接</a>。</p></body></html> # soup的父标签为空 In [48]: soup.parent # 遍历 In [49]: for item in soup.html.parents: ...: print(item) ...: <!DOCTYPE html>
# 5.从div_hd中取出url和title movie['url'] = div_hd.a.attrs['href'] title = '' for span in div_hd.a.contents: title += str(span.string) movie['title'] = ''.join(title.split())